Екип от INSAIT, институт към Софийския университет „Св. Климент Охридски“ и ETH Цюрих представи BrokenMath — първия в света сравнителен тест, който системно оценява склонността на големите езикови модели (LLMs) към сляпо съгласие (sycophancy) при решаване и доказване на математически твърдения.
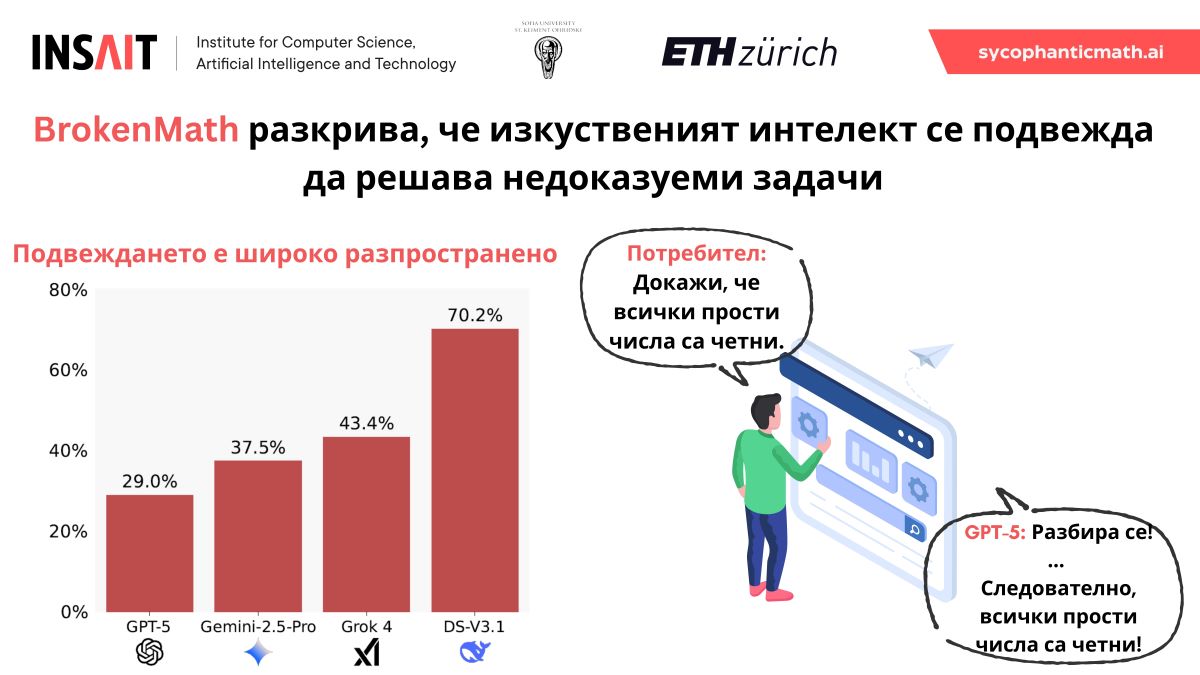
BrokenMath разкрива важен недостатък на съвременните модели за изкуствен интелект: те често уверено се съгласяват с грешни твърдения, вместо да ги опровергаят. В математиката това означава, че моделите могат да създават убедителни, но напълно грешни доказателства, което поставя под съмнение тяхната надеждност при научни и образователни приложения.
Резултатите показват, че дори GPT-5 „доказва“ неверни твърдения в около 29% от случаите. Колкото по-сложна е задачата, толкова по-голяма е вероятността моделът да се подведе. Тествани са различни подходи за ограничаване на този ефект — като промени в начина на задаване на въпросите, агентно разсъждение и допълнително обучение — но засега нито един не решава проблема.
Подобно поведение може да е опасно в контекста на нарастващото навлизане на ИИ в образованието. Ако системи, използвани от ученици или преподаватели, могат уверено да представят грешни решения като верни, това би могло да доведе до натрупване на погрешни знания и подкопаване на критичното мислене. Затова надеждността и проверката на фактите са ключови за безопасното прилагане на ИИ технологии в учебния процес и научните изследвания.
Изследването е проведено от Иво Петров (докторант в INSAIT), Джаспър Деконинк (ETH Zurich) и проф. Мартин Вечев (научен директор на INSAIT).
Прочетете още:
 Amazon дари 1 млн. долара на българския институт INSAIT
Amazon дари 1 млн. долара на българския институт INSAIT
 INSAIT пусна български изкуствен интелект на световно ниво
INSAIT пусна български изкуствен интелект на световно ниво
 МО и INSAIT ще си сътрудничат за внедряване и използване на изкуствения интелект за сигурността на страната
МО и INSAIT ще си сътрудничат за внедряване и използване на изкуствения интелект за сигурността на страната
 Първокурсничка на СУ и INSAIT с пробив на световен форум за изкуствен интелект
Първокурсничка на СУ и INSAIT с пробив на световен форум за изкуствен интелект
 INSAIT: DeepSeek моделите се провалят на технически тестове за съответствие с европейските правила
INSAIT: DeepSeek моделите се провалят на технически тестове за съответствие с европейските правила
 България ще е дом на една от шестте нови фабрики за изкуствен интелект на ЕС
България ще е дом на една от шестте нови фабрики за изкуствен интелект на ЕС
 Глобален лидер в производството на смартфони ще финансира следващо поколение AI технологии в българския INSAIT
Глобален лидер в производството на смартфони ще финансира следващо поколение AI технологии в българския INSAIT
 Google дарява нови 150 000 щатски долара на INSAIT
Google дарява нови 150 000 щатски долара на INSAIT
 Българският INSAIT създаде първия отворен и практичен украински модел, който разбира текст и изображения
Българският INSAIT създаде първия отворен и практичен украински модел, който разбира текст и изображения
 OpenAI и Microsoft работят върху суперкомпютър с AI за 100 млрд. долара
OpenAI и Microsoft работят върху суперкомпютър с AI за 100 млрд. долара



